


日前,JEDEC固态技术协会宣布,备受期待的高带宽存储器 (HBM) DRAM 标准的下一个版本:HBM4 即将完成。
据介绍,HBM4 是目前发布的 HBM3 标准的进化版,旨在进一步提高数据处理速率,同时保持基本特性,例如更高的带宽、更低功耗和更大的每个芯片和/或堆栈容量。这些进步对于需要高效处理大数据集和复杂计算的应用至关重要,包括生成人工智能 (AI)、高性能计算、高端显卡和服务器。
与 HBM3 相比,HBM4 计划将每个堆栈的通道数增加一倍,物理占用空间也更大。为了支持设备兼容性,该标准确保单个控制器可以在需要时同时与 HBM3 和 HBM4 配合使用。不同的配置将需要不同的中介层来适应不同的占用空间。HBM4 将指定 24 Gb 和 32 Gb 层,并可选择支持 4 高、8 高、12 高和 16 高 TSV 堆栈。
JEDEC指出,委员会已就高达 6.4 Gbps 的速度等级达成初步协议,目前正在讨论更高的频率。

HBM 4,有哪些更新?
高带宽内存已存在约十年,在其持续发展过程中,其速度稳步提升,数据传输速率从 1 GT/s(最初的 HBM)开始,到现在HBM3E的9 GT/s。这使得带宽在不到 10 年的时间里实现了令人瞩目的飞跃,使 HBM 成为此后投放市场的全新 HPC 加速器的重要基石。
但随着内存传输速率的提高,尤其是在 DRAM 单元的基本物理特性没有改变的情况下,这种速度也越来越难以维持。因此,对于 HBM4,该规范背后的主要内存制造商正计划对高带宽内存技术进行更实质性的改变,从更宽的 2048 位内存接口开始。
HBM4 将把内存堆栈接口从1024 位扩展至 2048 位,这将是自八年前推出这种内存类型以来 HBM 规范最重要的变化之一。将 I/O 引脚数量增加两倍,同时保持相似的物理占用空间,对于内存制造商、SoC 开发商、代工厂和外包组装和测试 (OSAT) 公司来说极具挑战性。

按照计划,这将使 HBM4 在多个层面上实现重大技术飞跃。在 DRAM 堆叠方面,2048 位内存接口将需要显著增加通过内存堆栈布线的硅通孔数量。同时,外部芯片接口将需要将凸块间距缩小到 55 微米以下,同时将微凸块总数从 HBM3 的当前数量(约)3982 个凸块大幅增加。
内存制造商表示,他们还将在一个模块中堆叠多达 16 个内存芯片,即所谓的 16-Hi 堆叠,这为该技术增加了一些复杂性。(HBM3 在技术上也支持16-Hi 堆叠,但到目前为止还没有制造商真正使用它)这将允许内存供应商显著增加其 HBM 堆栈的容量,但它带来了新的复杂性,即在无缺陷的情况下连接更多数量的 DRAM 芯片,然后保持最终的 HBM 堆栈适当且一致地短。而所有这一切反过来又需要芯片制造商、内存制造商和芯片封装公司之间更加紧密的合作,以使一切顺利进行。
不过,随着DRAM堆栈数量的增加,有人指出封装技术面临着局限性。
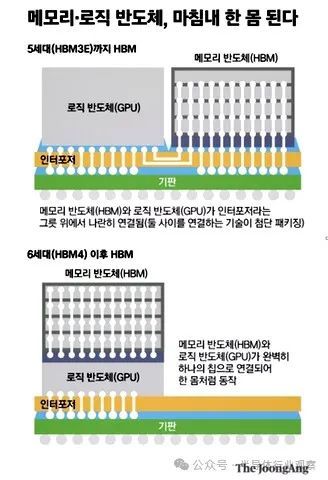
现有的HBM采用了TC(热压)键合技术,该技术在DRAM中创建TSV通道,并通过小突起形式的微凸块进行电连接。三星电子和海力士的具体方法有所不同,但相似之处在于都使用了凸点。
最初,客户将 DRAM 堆叠至多达 16 层,并要求 HBM4 最终封装厚度为 720 微米,与前几代产品相同。普遍的观点是,使用现有的接合实际上不可能在 720 微米处实现 16 层 DRAM 堆叠 HBM4。因此,业界关注的替代方案是混合键合。混合键合是一种在芯片和晶圆之间直接键合铜布线的技术。由于DRAM之间不使用凸块,因此更容易减小封装厚度。
然而,据韩国媒体在三月的报道,在当时的讨论中,相关公司决定将封装厚度标准放宽至775微米(μm),比上一代的720微米(μm)更厚。国际半导体标准组织(JEDEC)的主要参与者也同意将HBM4产品的标准定为775微米。如果封装厚度减少到775微米,即使使用现有的接合技术,也可以充分实现16层DRAM堆叠HBM4。考虑到混合键合的投资成本巨大,存储器公司很可能将重点放在升级现有键合技术上。
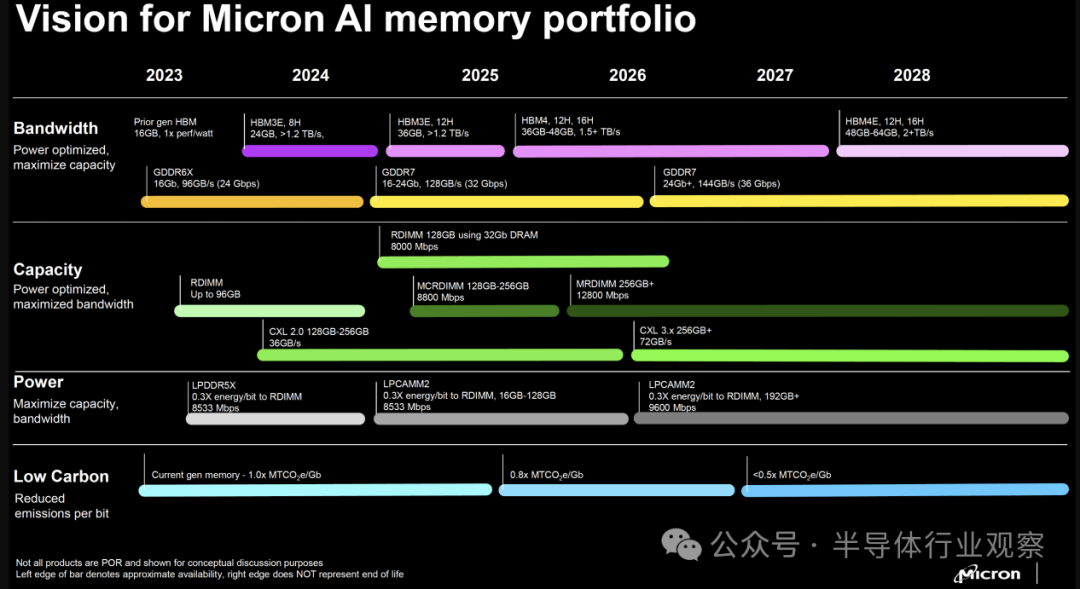
根据Trendforce 去年年底分享的路线图预计,首批 HBM4 样品预计每堆栈容量高达 36 GB,完整规格预计将由 JEDEC 在 2024-2025 年下半年左右发布。预计第一批客户样品和供货时间是 2026 年,因此我们还有很长一段时间才能看到新的高带宽内存解决方案投入使用。

三大巨头的最新布局
目前,市场上有SK Hynix、三星和美光这三大玩家,他们在HBM 4上也明争暗斗。
首先看SK Hynix方面,在五月的一次行业活动中表示,SK Hynix 表示,可能在 2025 年率先推出下一代 HBM4。SK Hynix 计划在 HBM4 的基础芯片中采用台积电的先进逻辑工艺,以便将额外的功能塞进有限的空间内,帮助 SK Hynix 定制 HBM,以满足更广泛的性能和能效要求。
与此同时,SK 海力士表示,双方还计划致力于优化其 HBM 和晶圆上芯片 (CoWoS,台积电的封装技术) 技术的组合,并满足客户的 HBM 需求。

在SK海力士看来,公司的HBM产品具备业界最佳的速度和性能。尤其是我们独有的MR-MUF技术,为高性能提供了最稳定的散热,为造就全球顶尖性能提供了保障。SK 海力士声称,大规模回流成型底部填充 (MR-MUF) 技术制造,比使用热压缩非导电膜(TC-NCF) 制造的产品坚固 60%。此外,公司拥有快速量产优质产品的能力,我们对客户需求的响应速度也是首屈一指的。这些竞争优势的结合使公司的HBM脱颖而出,跻身行业前列。
具体到DRAM方面,据报道,SK海力士计划将1b DRAM应用到HBM4,并从HBM4E应用1c DRAM。但据了解,SK海力士仍留有根据市场情况灵活改变应用技术的空间。
来到三星方面,作为一个追赶者,三星也火力全开。
三星电子在其设备解决方案 (DS) 部门内成立了新的“HBM 开发团队”,以增强其在高带宽内存 (HBM) 技术方面的竞争力。这一战略举措是在副董事长 Kyung-Hyun Kyung 就任 DS 部门负责人一个多月后采取的,反映了该公司致力于在快速发展的半导体市场中保持领先地位的决心。
新成立的 HBM 开发团队将专注于推进 HBM3、HBM3E 和下一代 HBM4 技术。该计划旨在满足人工智能 (AI) 市场扩张带来的对高性能内存解决方案的激增需求。今年早些时候,三星已经成立了一个工作组 (TF) 来增强其 HBM 竞争力,新团队将整合和提升这些现有的努力。
三星电子同时强调,将加强其定于明年发布的第六代高带宽内存(HBM4)的定制服务。
该公司内存事业本部新业务规划组副总裁Choi Jang-seok表示:“与HBM3相比,HBM4的性能显着提高”,并补充说:“我们正在扩大产能到 48GB(千兆字节)并以明年的生产目标进行开发。”
三星电子将MOSFET工艺应用到HBM3E,并正在积极考虑从HBM4开始应用FinFET工艺。因此,与 MOSFET 应用相比,HBM4 的速度提高了 200%,面积缩小了 70%,性能提高了 50% 以上。这是三星电子首次公开HBM4规格。
Choi 副总裁表示:“HBM 架构将发生重大变化。许多客户的目标是定制优化,而不是现有的通用用途。”他补充道,“例如,HBM DRAM 和定制逻辑芯片的 3D 堆叠显著提高。” “由于通用 HBM 的中介层和大量输入/输出 (I/O),将有可能降低性能并消除性能扩展的障碍,”他解释道。
他继续说道,“HBM不仅不能忽视性能和容量,还不能忽视功耗和热效率。为此,16层HBM4不仅采用了NCF之外的HCB(混合键合)技术等各种尖端封装技术(非导电粘合膜)组装技术,还有新工艺“正确实施各种新技术至关重要,三星正在按照计划进行准备,”他补充道。
有报道指出,三星电子最近在内部制定了一项计划,将原来计划安装在HBM4中1b DRAM改为1c DRAM。并将量产目标日期从明年年底提前到明年中下旬,但因为良率必须得到支持,此传言尚未得到证实。
另一家HBM参与者美光则预计在2025到2026年推出12H和16H的HBM4,其容量为 36GB 到 48GB ,速度为1.5TB/S以上。据美光称,HBM4 之后,HBM4E 将于 2028 年问世。HBM4 的扩展版本预计将获得更高的时钟频率,并将带宽提高到 2+ TB/s,容量提高到每个堆栈 48GB 到 64GB。
将高带宽内存加速至光速
HBM 的出现是为了向 GPU 和其他处理器提供比标准 x86 插槽接口所能支持的更多的内存。但 GPU 的功能越来越强大,需要更快地从内存中访问数据,以缩短应用程序处理时间——例如,大型语言模型 (LLM) 可能涉及在机器学习训练运行中重复访问数十亿甚至数万亿个参数,而这可能需要数小时或数天才能完成。

当前的 HBM 遵循相当标准的设计:HBM 内存堆栈通过微凸块连接到位于基础封装层上的中介层,微凸块连接到 HBM 堆栈中的硅通孔 (TSV 或连接孔)。中介层上还安装了一个处理器,并提供 HBM 到处理器的连接
HBM 供应商和 HBM 标准机构正在研究使用光子学等技术或直接将 HBM安装在处理器芯片上来加快 HBM 到处理器的访问速度。供应商正在设定 HBM 带宽和容量速度——似乎比 JEDEC 标准机构能够跟上的速度更快。
三星正在研究在中介层中使用光子技术,光子在链路上的流动速度比编码为电子的比特速度更快,而且功耗更低。光子链路可以以飞秒的速度运行。这意味着10-15单位时间——一千万亿分之一秒(十亿分之一的百万分之一)。

据韩国媒体报道,SK 海力士还在研究直接 HBM-逻辑连接概念。这一概念将 GPU 芯片与 HBM 芯片一起制造在混合用途半导体中。该芯片厂将此视为 HBM4 技术,并正在与 Nvidia 和其他逻辑半导体供应商进行谈判。这个想法涉及内存和逻辑制造商共同设计芯片,然后由台积电等晶圆厂运营商制造。
这有点类似于内存处理(PIM)的想法,除非受到行业标准的保护,否则将是专有的,具有供应商锁定的前景。
与三星和 SK 海力士不同,美光并未谈论将 HBM和逻辑集成到单个芯片中。它将告诉 GPU 供应商(AMD、英特尔和 Nvidia),他们可以使用组合的 HBM-GPU 芯片获得更快的内存访问速度,而 GPU 供应商将非常清楚专有锁定和单一来源的危险。
随着 ML 训练模型越来越大,训练时间越来越长,通过加快内存访问速度和增加每个 GPU 内存容量来缩短运行时间的压力也将同步增加。放弃标准化 DRAM 的竞争供应优势可靠股票配资网,获得锁定的 HBM-GPU 组合芯片设计(尽管速度和容量更好)可能不是前进的正确方法。

